本文共 4222 字,大约阅读时间需要 14 分钟。
目录
explain执行计划
数据库版本:SELECT VERSION() 5.7.18-log
官网:
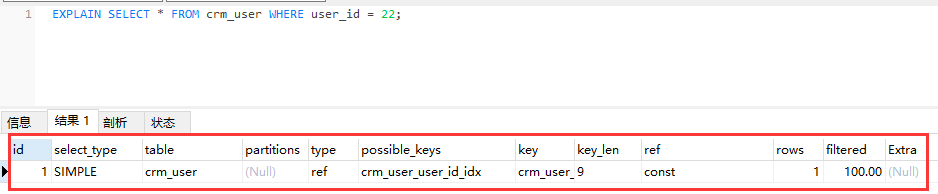
字段说明
| 字段 | 说明 |
|---|---|
| id | SQL执行的顺序的标识,越大越先执行,如果说数字一样大,那么就从上往下依次执行 |
| select_type | 查询类型,如:simple,primary,union,derived,subquery等 |
| table | 输出行所引用的表的名称,也可以是:union,derived,subquery |
| partitions | 访问的分区,没有分区 null |
| type | 联接类型,system > const > eq_ref > ref > (fulltext > ref_or_null > index_merge > unique_subquery > index_subquery) > range > index >all |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 实际用到的索引长度,null会比not null长度多1 |
| ref | 列或者常量被用于查找索引列上的值 |
| rows | 必须检查的用来返回请求数据的行数(估算值) |
| filtered | 满足查询的记录数量的比例 |
| Extra | 处理查询的额外信息 |
select_type
-
simple,简单select,不使用union或子查询
-
primary, 一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary
-
union, union中的第二个或后面的SELECT语句
-
dependent union,union中的第二个或后面的SELECT语句,依赖外部查询
-
union result,union的结果
-
subquery,子查询
-
dependent subquery,相关子查询,依赖外部查询
-
derived,派生表,
-
materialized,具体化的子查询
-
uncacheable subquery,子查询,其结果无法缓存,必须针对外部查询的每一行重新进行评估
-
uncacheable union,结果无法缓存
-
...
type:Join Types
-
system,表只有一行,const的特殊情况
-
const,使用主键和唯一索引时,返回一行记录;很快,只读取一次数据
-
eq_ref,多表连接使用主键或者唯一索引作为关联条件
-
ref, 查找非唯一性索引,返回匹配某一条件的多条数据。属于精确查找、数据返回可能是多条
-
range,索引的范围扫描
-
index,全索引扫描
-
all,全表扫描
-
...
Extra Information
-
Impossible WHERE ,where子句始终为false,查询不到任何行
-
Distinct,一旦找到了与行相联合匹配的行,就不再搜索了
-
Using filesort,需要进行额外的步骤来对返回行排序,常见于order by和group by语句中
-
Using index,不需要回表查询,直接通过索引就可以获得查询的数据
-
Using join buffer (Block Nested Loop),Using join buffer (Batched Key Access) ,优化关联查询的两个算法,主要是减少内表的循环次数以及比较顺序地扫描查询
-
Using MRR,使用到了 Multi-Range Read 优化策略,查询辅助索引时,对查询结果按照主键进行排序,再查询聚集索引。目的是将随机访问转化为较为顺序的顺序访问
-
Using temporary ,需要使用到临时表存储中间结果,常用于group by和order by
-
Using where,使用到了where过滤条件
摘自官网:

摘自网络:
Extra中看到了Using where,代表是按照where条件进行了过滤,和是否走索引、回表无必然的关系。 只有在使用了索引,且Extra是Using where的情况下,才代表回表查询数据。 还有一种情况,Extra中是using index & using where,表示select的数据在索引中能找到,但需要根据where条件过滤,这种情况也不回表。
-
..
sql编程
1. 简单来说,MySQL数据库的发展可以概括为三个阶段:
-
初期开源数据库阶段
-
Sun MySQL阶段
-
Oracle MySQL阶段
2. 一般来说,可将数据库的应用类型分为 OLTP(OnLine Transaction Processing ,联机事务处理) 和 OLAP(OnLine Analysis Processing,联机分析处理) 两种
-
OLTP主要执行基本的、日常的事务处理,比如在银行存取一笔款,就是一个事务交易
-
OLAP是数据仓库系统的主要应用,其典型的应用就是复杂的动态报表系统
-
衡量OLTP系统的一个重要性能指标是 系统性能 ,具体体现为实时响应时间(Response Time),即从用户在终端输入数据到计算机对这个请求做出回复所需的时间
3. MySQL数据库组成

5. InnoDB存储引擎
关于InnoDB存储引擎的技术详情,可以参见我的博客:
这里就只是简单地说一下!
-
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用
-
其特点是行锁设计、支持外键,并支持类似Oracle的非锁定读,即默认读取操作不会产生锁
-
从MySQL 5.5.8版本开始是默认的存储引擎
-
表空间、多版本并发控制(MVCC)(插入缓冲、二次写、自适应哈希索引、预读)、以聚集的方式存储数据
数据类型
摘取是一些我认为重要的知识点!
1. 如果一个页内可以存放尽可能多的行,那么数据库的性能就越好,因此选择一个正确的数据类型至关重要。
2. UNSIGNED属性
-
UNSIGNED属性就是将数字类型无符号化
例如,INT的类型范围是-2147483648~2147483647, INT UNSIGNED的范围类型就是0~4294967295
-
在MySQL数据库中,对于UNSIGNED数的操作,其返回值都是UNSIGNED的
-
尽量不要使用UNSIGNED,因为可能会带来一些意想不到的效果。另外,对于INT类型可能存放不了的数据,INT UNSIGNED同样可能存放不了,与其如此,还不如在数据库设计阶段将INT类型提升为BIGINT类型
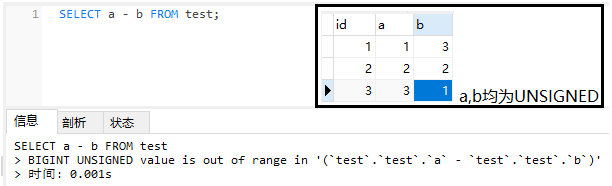
3. ZEROFILL属性
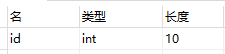
可以看到int(10),这代表什么意思呢?整型不就是4字节的吗?这10又代表什么呢?其实如果没有ZEROFILL这个属性,括号内的数字是毫无意义的。
ZEROFILL属性的作用,如果宽度小于设定的宽度(这里的宽度为4),则自动填充0。要注意的是,这只是最后显示的结果,在MySQL中实际存储的还是1。
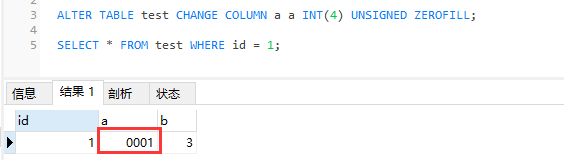
ZEROFILL可以格式化显示整型,一旦启用ZEROFILL属性,MySQL数据库为列自动添加UNSIGNED属性。
4. 数据类型
MySQL数据库支持两种浮点类型:单精度的FLOAT类型及双精度的DOUBLE PRECISION类型。
这两种类型都是非精确的类型,经过一些操作后并不能保证运算的正确性,例如 M*G/G不一定等于M 。
DECIMAL和NUMERIC类型在MySQL中被视为相同的类型,用于保存必须为确切精度的值。
位类型,即BIT数据类型可用来保存位字段的值。BIT(M)类型表示允许存储M位数值,M范围为1到64,占用的空间为(M+7)/8字节。
5. Unicode字符编码
Unicode是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言和跨平台进行文本转换和处理的要求。
需要注意的是,Unicode是字符编码,不是字符集。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0~0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。utf8、utf16和utf32都是将数字转换到程序数据的编码方案。
对于Unicode编码的字符集,强烈建议将所有的CHAR字段设置为VARCHAR字段,因为对于CHAR字段,数据库会保存最大可能的字节数。
有一些常用的命名规则。如:
_ci结尾表示大小写不敏感(case insensitive
_cs表示大小写敏感(case sensitive)
_bin表示二进制的比较(binary)。
utf8字符集默认的排序规则是utf8_general_ci。
6. CHAR 和 VARCHAR(★)
CHAR(N)和VARCHAR(N)中的N都代表字符长度,而非字节长度。
对于CHAR类型的字符串,MySQL数据库会自动对存储列的右边进行填充(Right Padded)操作,直到字符串达到指定的长度N。而在读取该列时,MySQL数据库会自动将填充的字符删除。
LENGTH函数返回的是字节长度,而不是字符长度。
对于多字节字符集,CHAR(N)长度的列最多可占用的字节数为该字符集单字符最大占用字节数*N。
gbk字符集中的中文字符占用两个字节。
VARCHAR类型存储变长字段的字符类型,与CHAR类型不同的是,其存储时需要在前缀长度列表加上实际存储的字符,该字符占用1~2字节的空间。当存储的字符串长度小于255字节时,其需要1字节的空间,当大于255字节时,需要2字节的空间。
对于有些多字节的字符集类型,其CHAR和VARCHAR在存储方法上是一样的,同样需要为长度列表加上字符串的值。对于GBK和UTF-8这些字符类型,其有些字符是以1字节存放的,有些字符是按2或3字节存放的,因此同样需要1~2字节的空间来存储字符的长度。
BINARY(N)和VARBINARY(N)中的N指的是字节长度,而非CHAR(N)和VARCHAR(N)中的字符长度。
7. 行溢出数据
没有详说,具体的可以参看我的另外一篇博客:
在数据库中,最小的存储单元是页(也可以称为块)。为了有效存储列类型为BLOB或TEXT的大数据类型,一般将列的值存放在行溢出页,而数据页存储的行数据只包含BLOB或TEXT类型数据列前一部分数据。
转载地址:http://fiqen.baihongyu.com/